We don’t know if you noticed, but the LINA research field (LIterary Network Analysis) has come up with pretty good PR videos lately. Look at this fancy Youtube clip produced by the “Nation, Genre & Gender” project at the University College Dublin (their project homepage is here). The NG+G project applies Social Network Analysis to Irish and British Fiction (1800–1922), their corpus involves 46 novels from 29 authors (according to the video they identified 9,630 unique fictional characters). And although the automated extraction of characters from novels has made progress in recent years (see, for example, Jannidis et al.’s paper from DH2016), it is still rough on many edges. That’s why the UCD project chose manual annotation as their approach, and that’s why their data is of such high quality (but also limited in scope).
If you’re working with dramatic texts, automated character extraction is far less of a problem, since this kind of texts comes pre-structured, so to speak. If you work with one of the many TEI-tagged corpora it is even easier to pull out interactions and start analysing them with network metrics. Although, admittedly, sometimes it’s harder than it seems, depending on the quality and depth of the mark-up (we covered that issue in multiple postings last year).
But what do you do if you can’t rely on a fine-grained TEI corpus? That’s what we’re confronted with when gathering network data from Russian drama. If you assemble all the plays that you can find on lib.ru, rvb.ru and ru.wikisource.org, you got yourself a pretty good working corpus. The sustainable way would be to assemble all the works and then transform them into TEI and share it with the community. But corpus building is a task of its own and needs a lot of dedication. And after all, we “just” need some kind of network data, not a polished digital edition of the works. So one idea to go forward is to exploit the HTML structure of the texts.
Mayakovsky’s “The Bedbug”
In the beginning of July, we taught a Network Analysis course at the First Moscow-Tartu Digital Humanities Summer School in Yasnaya Polyana (if you speak Russian, slides are here). Originally, we wanted to analyse 19th-century drama, but one of the participants preferred to confront our methods with one of Vladimir Mayakovsky’s plays (hi G.! :-). He chose “Klop” (translated as “The Bedbug”, see en.wikipedia.org; an English adaption by Snoo Wilson is here as PDF; a concise English summary can be found at sovlit.net), written in 1928 and first published the year after.
“Klop” is definitely one of the challenging plays when it comes to character extraction. And now, two months after the summer school, we tried to automatise the extraction process and used “Klop” as an example. Before we get into the details, this is the end result (visualised in Gephi 0.9.1 using its built-in modularity algorithm; the image is licensed under CC BY 4.0):
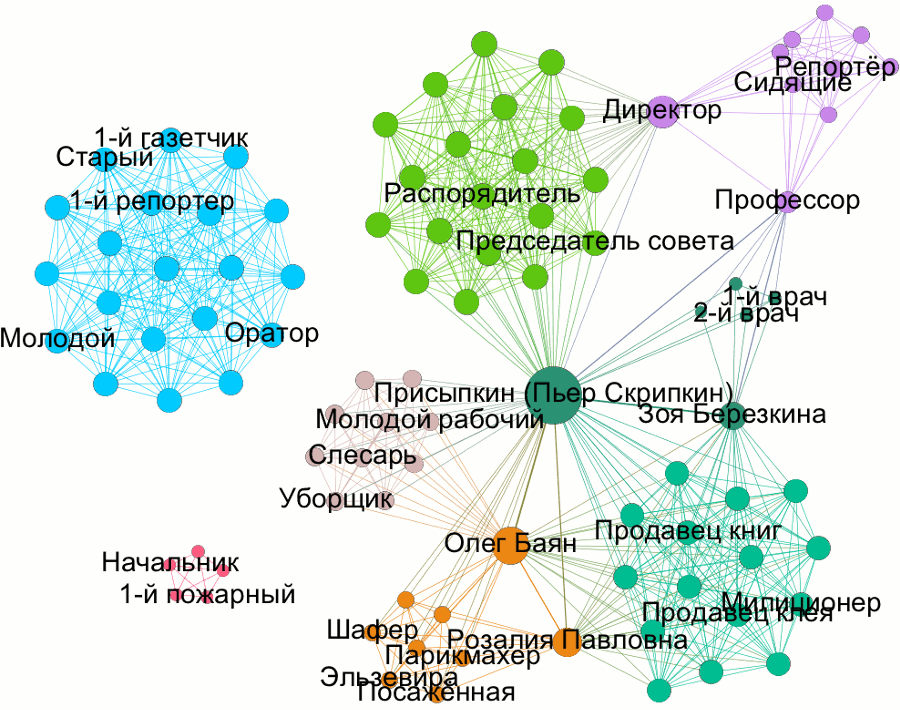
Network-Driven Synopsis
It’s the late 1920s in a mid-sized town in Soviet Russia. The protagonist in “Klop”, “Pierre Skripkin” (who changed his name from “Prisypkin”), abandons his socialist ideals, because after all the fighting and suffering he wants to start benefiting from what has been achieved. And because this is such an unusual play, we can actually base our synopsis on the network graph. The play consists of nine scenes:
- In scene 1, we see Skripkin (dark-green, central node) with his friend Bayan and his soon-to-be mother-in-law Rozaliya (both orange) strolling through a warehouse where merchants praise their products (dark-green cluster).
- In scene 2, Skripkin discusses his lifestyle with the characters in the light-brown/beige cluster.
- Scene 3 shows Skripkin’s wedding with his bourgeois bride Elsevira (orange cluster). However, fire breaks out and everybody dies, except for Skripkin who, …
- … in scene 4, goes unnoticed by the firefighters and is preserved in the icy water in the cellar. The firefighters and their captain are depicted in the red cluster, which is detached from the other clusters.
- In scene 5, the play reaches the future, jumping 50 years ahead in time. It is now the end of the 1970s, a global socialist state has been created (kind of an aseptic one, though). We follow a call-in discussion among several participants led by an operator, depicted in the light-blue cluster. It is discussed if Skripkin’s recovered body shall be defrosted or not, and a majority votes in favour of unfreezing. Just like the red cluster, this light-blue one is also detached from the main cluster. So the transitional scenes between present and future are detached, character-wise, from the rest of the play, which is a nice structure-related finding: Skripkin is kind of tunnelling through these scenes into the 1970s.
- In scene 6, we meet Skripkin’s ex-girlfriend Zoya Beryozkina, who already occurred in the first two scenes and who is the only other person next to Skripkin who makes it from the present to the future in this play. She shares scene 6 with the professor (purple), some doctors (dark-green) and the resurrected protagonist.
- In scene 7, we see a journalist reporting about the “resurrected mammal” (purple cluster). It is said that Skripkin is dangerous since he started to spread these ancient diseases among the people (like dancing, drinking beer and falling in love). In the same scene, the equally dangerous bedbug, which was defrosted along with Skripkin, is hunted down. The eponymous insect, which clearly serves as a symbol in the play, is not featured in the network graph, since no speech act can be attributed to it. 😉 (Although you might well think of a different approach including the little bug in the network analysis.)
- Scene 8 presents a disappointed Skripkin who doesn’t like this aseptic future and declares that he would have preferred to stay frozen. The scene is mainly shared between him, Zoya and the professor.
- Scene 9 takes place in the zoo, where Skripkin and the bedbug are presented as attractions (light-green cluster). When Skripkin is released from his cage, he holds a speech, but people are appalled and he’s put behind bars again and, further on, “displayed as a specimen of society’s primitive past, where school children can feed him with cigarettes and alcohol” (dramaonlinelibrary.com).
Extracting the Network Data
Coming back to where we started, how did we extract the character network: The play was digitised at Wikisource. After having a closer look at the underlying HTML it was clear that extraction was easy, we just needed clear indicators for the beginning of a new scene and all speakers involved. A little Bash script (making use of xmllint) extracted the info like this:
I
Разносчик пуговиц
Разносчик кукол
Разносчица яблок
(…)
Присыпкин (Пьер Скрипкин)
Розалия Павловна
Присыпкин (Пьер Скрипкин)
Баян
(…)
II
Босой
Уборщик
Босой
Молодой рабочий
Девушка
Парень
(…)
III
Эльзевира
Присыпкин (Пьер Скрипкин)
Эльзевира
Присыпкин (Пьер Скрипкин)
Гость
(…)Disambiguation
Now came the tricky part. Since we’re relying on character names, just like the author put them in his play, we had to deal with plenty of ambiguities. This wouldn’t happen with proper TEI, when every <sp>eech act provides IDs for all involved characters. An additional problem is that you have different entities going by the same name, like “Голоса” (“Voices”) in the second and third scene.
So what we had to account for to get a really clean character network is the following:
- “Зоя” = “Зоя Берёзкина”
- “Присыпкин” and “Скрипкин” where combined to “Присыпкин (Пьер Скрипкин)” (since the protagonist proactively changed his name, see above)
- 1st scene: “Пуговичный разносчик” = “Разносчик пуговиц”
- 2nd scene: “Босой парень” and “Босой” are the same
- 2nd scene: “Молодой рабочий” and “Парень” are the same (just like “Парень с метлой”)
- 2nd scene: the “Девушка” in this scene is not the same as in scene 7 (disambiguation by numbering)
- 3rd scene: “Посажёный отец—бухгалтер” = “Бухгалтер”
- 3rd scene: “Крики” at the end eliminated
- 4th scene: “Пожарные” deleted (for the same reasons for which “Все” was deleted)
- 5th scene: “Старший и младший” deleted
- 5th scene: the incoming messages from the several outposts are not marked with their speakers (as a result, they don’t appear in the network)
- 6th scene: “Хором” deleted
- 9th scene: “Голос из толпы” occurs three times, all voices are apparently different, so we numbered them
- 9th scene: “Председатель совета” and “Председатель” are the same
We also eliminated all occurrences of “Все” (“All”): the idea is that characters contained in the “Все” already participate in the corresponding scene. That way, we avoid having “Все” as an additional character in the network. For the same reason we could have eliminated all occurrences of “Голоса” (“Voices”), but that’s a different thing since voices can come from unmentioned characters that don’t otherwise contribute to a speech act. So we let those in.
(The resulting TXT file can be found here: “mayakovsky-klop-speakers-per-scene.txt”.)
In comparison, the intermediary XML format we introduced when starting to work with our corpus of German drama can be much more fine-grained, because we’re working with a TEI-encoded corpus there. One of the purposes of this article, though, is to demonstrate that you can already do stuff with the most basic of interactional data.
Building the CSV File
After we had cleaned the names of all speakers, we wrote another small script, this time in Python, to generate a CSV file containing all the edges of the network, here’s a little excerpt:
Source,Target,Weight
Баян,Босой,1
Баян,Бухгалтер,1
Баян,Голос,1
Баян,Голоса II,1
Баян,Голоса III,1
(…)
Баян,Присыпкин (Пьер Скрипкин),3
(…)Really just containing info on who is talking to whom in how many scenes. (The CSV file can be obtained here: “mayakovsky-klop-edges.csv”. This, of course, was the data we fed into Gephi to visualise the network shown above.)
Some Network Values
The network graph does well in demonstrating the structural uniqueness of Mayakovsky’s play. It is rather unusual that almost every scene can be identified as an individual cluster in the graph. The number of characters (= network size) is 94, the network density is fairly low, 0.17 (i.e., 17% of all possible connections between nodes are actually happening). The node-degree distribution shows traits of a power law, but it’s hard to draw any conclusions from that, since the play is so short and the interactional mode of the play so unique.
If you have a look at the CSV file, almost all weights are “1”, meaning that characters share exactly one scene. The play is really about showing Pierre Skripkin in different contexts, in the present and the future. His closest contacts are his former lover Zoya Beryozkina and Oleg Bayan (3 shared scenes each), Rozaliya Pavlovna (bride’s mother) and the professor in the future (2 shared scenes each).
Something Like a Conclusion
You cannot reflect enough on the practice of character extraction from literary texts. The method you use has a big impact on the numbers that you’re working with later. You not only have to “know your corpus”, but you also have to keep in mind the rationale on which you based the information extraction. Especially if you want to process not just one file (like we did in this post) but hundreds or thousands of them.

